Коэффициент детерминации r 2. Оценка результатов линейной регрессии
Рассмотрим вначале коэффициент детерминации для простой линейной регрессии, называемый также коэффициентом парной детерминации.
На основе соображений, изложенных в разделе 3.1, теперь относительно легко найти меру точности оценки регрессии. Мы показали, что общую дисперсию можно разложить на две составляющие - на «необъясненную» дисперсию и дисперсию обусловленную регрессией. Чем больше по сравнению с тем больше общая дисперсия формируется за счет влияния объясняющей переменной х и, следовательно, связь между двумя переменными у их более интенсивная. Очевидно, удобно в качестве показателя интенсивности связи, или оценки доли влияния переменной х на использовать отношение

Это отношение указывает, какая часть общего (полного) рассеяния значений у обусловлена изменчивостью переменной х. Чем большую долю в общей дисперсии составляет тем лучше выбранная функция регрессии соответствует эмпирическим данным. Чем меньше эмпирические значения зависимой переменной отклоняются от прямой регрессии, тем лучше определена функция регрессии. Отсюда происходит и название отношения (3.6) - коэффициент детерминации Индекс при коэффициенте указывает на переменные, связь между которыми изучается. При этом вначале в индексе стоит обозначение зависимой переменной, а затем объясняющей.
Из определения коэффициента детерминации как относительной доли очевидно, что он всегда заключен в пределах от 0 до 1:
![]()
Если то все эмпирические значения (все точки поля корреляции) лежат на регрессионной прямой. Это означает, что для В этом случае говорят о строгом линейном соотношении (линейной функции) между переменными у их. Если дисперсия, обусловленная регрессией, равна нулю, а
«необъясненная» дисперсия равна общей дисперсии. В этом случае Линия регрессии тогда параллельна оси абсцисс. Ни о какой численной линейной зависимости переменной у от в статистическом ее понимании не может быть и речи. Коэффициент регрессии при этом незначимо отличается от нуля.
Итак, чем больше приближается к единице, тем лучше определена регрессия.
Коэффициент детерминации есть величина безразмерная и поэтому он не зависит от изменения единиц измерения переменных у и х (в отличие от параметров регрессии). Коэффициент не реагирует на преобразование переменных.
Приведем некоторые модификации формулы (3.6), которые, с одной стороны, будут способствовать пониманию сущности коэффициента детерминации, а с другой стороны, окажутся полезными для практических вычислений. Подставляя выражение для в (3.6) и принимая во внимание (1.8) и (3.1), получим:
![]()
Эта формула еще раз подтверждает, что «объясненная» дисперсия, стоящая в числителе (3.6), пропорциональна дисперсии переменной х, так как является оценкой параметра регрессии.
Подставив вместо его выражение (2.26) и учитывая определения дисперсий а также средних х и у, получим формулу коэффициента детерминации, удобную для вычисления:


Из (3.9) следует, что всегда С помощью (3.9) можно относительно легко определить коэффициент детерминации. В этой формуле содержатся только те величины, которые используются для вычисления оценок параметров регрессии и, следовательно, имеются в рабочей таблице. Формула (3.9) обладает тем преимуществом, что вычисление коэффициента детерминации по ней производится непосредственно по эмпирическим данным. Не нужно заранее находить оценки параметров и значения регрессии. Это обстоятельство играет немаловажную роль для последующих исследований, так как перед проведением регрессионного анализа мы можем проверить, в какой степени определена исследуемая регрессия включенными в нее объясняющими
переменными. Если коэффициент детерминации слишком мал, то нужно искать другие факторы-переменные, причинно обусловливающие зависимую переменную. Следует отметить, что коэффициент детерминации удовлетворительно отвечает своему назначению при достаточно большом числе наблюдений. Но в любом случае необходимо проверить значимость коэффициента детерминации. Эта проблема будет обсуждаться в разделе 8.6.
Вернемся к рассмотрению «необъясненной» дисперсии, возникающей за счет изменчивости прочих факторов-переменных, не зависящих от х, а также за счет случайностей. Чем больше ее доля в общей дисперсии, тем меньше, неопределеннее проявляется соотношение между у и х, тем больше затушевывается связь между ними. Исходя из этих соображений мы можем использовать «необъясненную» дисперсию для характеристики неопределенности или неточности регрессии. Следующее соотношение служит мерой неопределенности регрессии:

Легко убедиться в том, что
![]()
![]()
Отсюда очевидно, что не нужно отдельно вычислять меру неопределенности, а ее оценку легко получить из (3.11).
Теперь вернемся к нашим примерам и определим коэффициенты детерминации для полученных уравнений регрессий.
Вычислим коэффициент детерминации по данным примера из раздела 2.4 (зависимость производительности труда от уровня механизации работ). Используем для этого формулу (3.9), а промежуточные результаты вычислений заимствуем из табл. 3:
Отсюда заключаем, что в случае простой регрессии 93,8% общей дисперсии производительности труда на рассматриваемых предприятиях обусловлено вариацией показателя механизации работ. Таким образом, изменчивость переменной х почти полностью объясняет вариацию переменной у.
Для этого примера коэффициент неопределенности т. е. только 6,2% общей дисперсии нельзя объяснить зависимостью производительности труда от уровня механизации работ.
Вычислим коэффициент детерминации по данным примера из раздела 2.5 (зависимость объема производства от основных фондов). Необходимые
промежуточные результаты вычислений приведены в разделе 2.5 при определении оценок коэффициентов регрессии:
Таким образом, 91,1% общей дисперсии объема производства исследуемых предприятий обусловлено изменчивостью значений основных фондов на этих предприятиях. Данная регрессия почти полностью исчерпывается включенной в нее объясняющей переменной. Коэффициент неопределенности составляет 0,089, или 8,9%.
Следует отметить, что приведенные в данном разделе формулы предназначены для вычисления по результатам выборки большого объема коэффициента детерминации в случае простой регрессии. Но чаще всего приходится довольствоваться выборкой небольшого объема . В этом случае вычисляют исправленный коэффициент детерминации учитывая соответствующее число степеней свободы. Формула исправленного коэффициента детерминации для общего случая объясняющих переменных будет приведена в следующем разделе. Из нее легко получить формулу исправленного коэффициента детерминации в случае простой регрессии
Суть состоит в следующем: этот показатель измеряет меру зависимости вариации одной величины от многих других. Он применяется для оценки качества линейной регрессии.
Формула расчета:
R^2 \equiv 1-{\sum_i (y_i — f_i)^2 \over \sum_i (y_i-\bar{y})^2},
- \bar{y} – ср. арифметическое зависимой переменной;
- fi – знач. зависимой переменной, предполагаемое по уравнению регрессии;
- yi – значение исследуемой зависимой переменной.
Детерминация, что это такое — определение
Коэффициент детерминации – часть дисперсии переменной (зависимой), которая обуславливается конкретной моделью зависимости. Так эта единица поможет вычесть долю необъясненной дисперсии в дисперсии зависимой переменной.
Данный показатель может принимать значения в пределах от 0 до 1. Чем его значение ближе к 1, тем связаннее результативный признак с исследуемыми факторами.
Т.к. преступление является результатом связи поведения и личностных качеств, этот показатель в деятельности заинтересованных органов рассчитывается для оценки качества преступного поведения, дает представление, что послужило вероятностной причиной преступления, что является мотивацией, какие этому были причины и условия.
Коэффициент детерминации, что показывает?
Этот коэффициент показывает варианты результативного признака от влияния факторного признака, он тесно связан с числом корреляции. Если связь отсутствует, то показатель равняется нулю, при ее наличии – единице.
Есть определение детерминизма как принципа устройства мира. Основой этого представления является взаимосвязанность всех явления. Это учение отрицает существование вещей вне взаимосвязи с миром.
Противоположностью является индетерминизм, он связан с отрицанием объективных отношений детерминации, или отрицанием причинности.
Генетический детерминизм – вера в то, что любой организм развивается под генетическим контролем.
Под детерминантами преступности в криминологии понимают социальные явления, действия которых могут вызвать преступность.
С помощью расчетов такого рода можно оценить вероятностное социокультурное влияние различных факторов на развитие личности и предположить, как себя будет вести человек, например, в деловом общении, объективно оценить, подходит ли он для государственного управления, или воинской службы.
Так же коэффициент определяет, правильно ли выбран индекс для подсчета коэффициентов бета и альфа. Если в % цифра ниже 75 к определенному индексу, значения бета и альфа к нему будут некорректны.
Индекс детерминации
Индекс детерминации – это квадрат инд. корреляции нелинейных связей. Этим значением характеризуют, на какое количество процентов моделью регрессии объясняются варианты показателей результативной переменной по отношению к своему среднему уровню.
Формула

Коэффициент детерминации скорректированный
Суть данного понятия состоит в следующем: этот индекс показывает долю дисперсии (общей) результативной переменной, объясняющей вариантами факторных переменных, включаемых в модель регрессии: (с увеличением, уменьшением).
Как уж ранее отмечалось, в случае линейной регрессии основными показателями качества построенного уравнения регрессии служат коэффициент детерминации и критерий Фишера. Использование этих показателей обосновывается в теории дисперсионного анализа. Здесь рассматриваются следующие суммы:
· – общая сумма квадратов отклонений зависимой переменной от средней (TSS );
·  – сумма квадратов, обусловленная регрессией (RSS
);
– сумма квадратов, обусловленная регрессией (RSS
);
· – сумма квадратов, характеризующая влияние неучтенных факторов (ESS ).
Напомним, что для моделей, линейных относительно параметров, выполняется следующее равенство
Исходя из этого равенства, вводился коэффициент детерминации
 . (6.22)
. (6.22)
В силу определения R 2 принимает значения между 0 и 1, . Чем ближе R 2 к единице, тем лучше регрессия аппроксимирует эмпирические данные , тем теснее наблюдения примыкают к линии регрессии. Если R 2 =1, то эмпирические точки (x i ,y i) лежат на линии регрессии и между переменными Y и X существует функциональная зависимость . Если R 2 =0, то вариация зависимой переменной полностью обусловлена воздействием неучтённых в модели переменных . Величина R 2 показывает, какая часть (доля) вариации зависимой переменной обусловлена вариацией объясняющей переменной .
Однако для моделей, нелинейных относительно параметров, равенство (6.21) не выполняется , т.е. . В связи с этим может получиться, что или . Это означает, что коэффициент детерминации, определяемый по формулам (6.22), может быть больше единицы или меньше нуля. Следовательно, R 2 для нелинейных моделей не является вполне адекватной характеристикой качества построенного уравнения регрессии.
На практике обычно в качестве коэффициента детерминации принимается величина
Эта величина имеет тот же самый смысл, что и для линейной модели, но при его использовании нужно учитывать все рассмотренные выше оговорки.
Замечание. Величину R 2 для нелинейных моделей иногда называют индексом детерминации , корень из данной величины R называют индексом корреляции.
Если после преобразования нелинейное уравнение регрессии принимает форму линейного парного уравнения регрессии, то для оценки тесноты связи может быть использован линейный коэффициент корреляции , где z – преобразованная величина независимой переменной, например z =1/x или z =lnx .
Иначе обстоит дело, когда преобразования уравнения в линейную форму связаны с результативным признаком. В этом случае линейный коэффициент корреляции по преобразованным значениям даёт лишь приближённую оценку тесноты связи и численно не совпадает с индексом корреляции.
Вследствие близости результатов и простоты расчётов с использованием компьютерных программ для характеристики тесноты связи по нелинейным функциям широко используется линейный коэффициент корреляции ( или ). Несмотря на близость значений R yx и или R yx и , следует помнить, что эти значения не совпадают. Это связано с тем, что для нелинейной регрессии , в отличие от линейной регрессии .
Коэффициент детерминации можно сравнивать с квадратом коэффициента корреляции для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . Близость этих показателей означает, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию. Практически, если величина ( – ) не превышает 0,1, то предположение о линейной форме связи считается оправданным. В противном случае проводится оценка существенности различия этих показателей, вычисленных по одним и тем же исходным данным.
Коэффициент детерминации можно использовать при сравнении двух альтернативных уравнений регрессии. Можно выбрать наилучшую из них по максимальному значению коэффициента детерминации. При рассмотрении альтернативных моделей с одним и тем же определением зависимой переменной предложенный способ выбора достаточно проста и очевидна. Однако нельзя сравнивать, например, линейную и логарифмические модели. Значения lnY значительно меньше соответствующих значений Y , поэтому неудивительно, что остатки также значительно меньше, но это ничего не решает. Величина R 2 безразмерна, однако в двух уравнениях она относится к разным понятиям. В одном уравнении она измеряет объясненную регрессией долю дисперсии Y , а в другом – объясненную регрессией долю дисперсии lnY . Если для одной модели коэффициент R 2 значительно больше, чем для другой, то можно сделать оправданный выбор без особых раздумий, однако, если значения R 2 для двух моделей приблизительно равны, то проблема выбора существенно усложняется.
Более подробно проблемы спецификации рассматриваются в дополнении 3.
Отметим, что критерий Фишера можно применять только для нормальной линейной классической регрессионной модели . Однако в общем случае, в первую для моделей нелинейных по параметрам, критерий Фишера применять нельзя! Иногда критерий Фишера применяют для линеаризованных моделей, однако здесь следует помнить, что исходное и линеаризованное уравнения не одно и то же, т.е. здесь нужны серьезные оговорки.
Более подробно использования критерия Фишера для линеаризированных моделей смотрите в дополнении 2.
ПРИМЕРЫ
Пример 6.1. Вычислить полулогарифмическую функцию регрессии зависимости доли расходов на товары длительного пользования в общих расходах семьи (Y , %) от среднемесячного дохода семьи (X , тыс. $ ):
| X | ||||||
| Y | 13,4 | 15,4 | 16,5 | 18,6 | 19,3 |
Решение. Используем стандартные процедуры линейного регрессионного анализа. Для расчетов воспользуемся данными таблицы 6.1:
Табл. 6.1.
| № | x | u= lnx | y | uy | u 2 | y 2 | A | |||
| 9,88 | 0,12 | 1,241 | 0,0154 | |||||||
| 0,693 | 13,4 | 9,29 | 0,48 | 179,56 | 13,43 | -0,03 | 0,232 | 0,0010 | ||
| 1,099 | 15,4 | 16,92 | 1,21 | 237,16 | 15,51 | -0,11 | 0,718 | 0,0122 | ||
| 1,386 | 16,5 | 22,87 | 1,92 | 272,25 | 16,99 | -0,49 | 2,946 | 0,2363 | ||
| 1,609 | 18,6 | 29,94 | 2,59 | 345,96 | 18,13 | 0,47 | 2,524 | 0,2203 | ||
| 1,792 | 19,1 | 34,22 | 3,21 | 364,81 | 19,07 | 0,03 | 0,180 | 0,0012 | ||
| Итого | 6,579 | 113,24 | 9,41 | 1499,74 | 7,840 | 0,4864 | ||||
| Среднее значение | 3,5 | 1,097 | 15,5 | 18,87 | 1,57 | 249,96 | 1,307 |
В соответствии с формулами (6.103) вычисляем
![]() , .
, .
В результате, получим уравнение полулогарифмической регрессии:

Подставляя в уравнение (6.24) фактические значения x i , получаем теоретические значения результата . Используя программу Excel ,
| ВЫВОД ИТОГОВ | |||||||
| Регрессионная статистика | |||||||
| Множественный R | 0,9958 | ||||||
| R -квадрат | 0,9916 | ||||||
| Нормированный R -квадрат | 0,9896 | ||||||
| Стандартная ошибка | 0,3487 | ||||||
| Наблюдения | |||||||
| ДИСПЕРСИОННЫЙ АНАЛИЗ | |||||||
| df | SS | MS | F | Значимость F | |||
| Регрессия | 57,75 | 57,75 | 474,93 | 0,000026 | |||
| Остаток | 0,49 | 0,12 | |||||
| Итого | 58,24 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y -пересечение | 9,8759 | 0,2947 | 33,51 | 0,0000047 | 9,0576 | 10,6942 |
| Переменная lnX | 5,1289 | 0,2353 | 21,79 | 0,0000262 | 4,4755 | 5,7823 |
Из этих данных видно, в частности, что все коэффициенты регрессии статистически значимы. Оценим качество уравнения регрессии. Рассчитаем среднюю ошибку аппроксимации
![]() ,
,
т.е. с точки зрения этого показателя уравнение регрессии подобрано очень хорошо.
Вычислим теперь средний коэффициент эластичности
Таким образом, при возрастании среднемесячного дохода семьи на 1% доля расходов на товары длительного пользования в общих расходах семьи возрастет на 0,25% .
Коэффициент детерминации для данной модели совпадает с квадратом коэффициента корреляции . По данным таблицы 6.3 получаем
И ![]() .
.
Коэффициент детерминации показывает, что уравнение регрессии на 99% объясняет вариацию значений признака y , т.е. с точки зрения коэффициента детерминации построенное уравнение регрессии очень хорошо описывает исходные данные.
Для оценки качества данной модели можно использовать критерий Фишера (при предположении, что мы имеем дело с нормальной классической линейной моделью). В этом случае получаем
,  .
.
Поскольку F набл >F крит , то гипотеза о случайной природе оцениваемых параметров отклоняется и признается их статистическая значимость и надежность, т.е. построенное уравнение регрессии признается статистически значимым. â
Пример 6.2. Имеются данные о просроченной задолженности по заработной плате за 9 месяцев 2000 г. по Санкт-Петербургу.
![]() . Оцените качество построенной регрессии. б) Оцените МНК коэффициенты обратной модели
. Оцените качество построенной регрессии. б) Оцените МНК коэффициенты обратной модели ![]() , линеаризуя модель. Оцените качество построенной регрессии. в) Оцените МНК коэффициенты обратной модели
, линеаризуя модель. Оцените качество построенной регрессии. в) Оцените МНК коэффициенты обратной модели ![]() , используя численные методы (метод Маркуардта)? г) Проанализируйте полученные результаты.
, используя численные методы (метод Маркуардта)? г) Проанализируйте полученные результаты.
Решение. а) Используя стандартные процедуры линейного регрессионного анализа (считая, как обычно, t =1 для января 2000 г.), получим:
| ВЫВОД ИТОГОВ | |||||||
| Регрессионная статистика | |||||||
| Множественный R | 0,846 | ||||||
| R -квадрат | 0,716 | ||||||
| Нормированный R -квадрат | 0,675 | ||||||
| Стандартная ошибка | 12,233 | ||||||
| Наблюдения | |||||||
| ДИСПЕРСИОННЫЙ АНАЛИЗ | |||||||
| df | SS | MS | F | Значимость F | |||
| Регрессия | 2640,07 | 2640,07 | 17,64 | 0,00403 | |||
| Остаток | 1047,58 | 149,65 | |||||
| Итого | 3687,64 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | ||
| Y-пересечение | 410,12 | 8,89 | 46,15 | 5,87E-10 | 389,11 | 431,14 | |
| Переменная X 1 | -6,63 | 1,58 | -4,20 | 4,03E-03 | -10,37 | -2,90 | |
![]() ,
,
 |
причём все коэффициенты регрессии значимы. Коэффициент детерминации равен , т.е. линейная модель удовлетворительно описывает исходные данные. На графике поле корреляции и линейное уравнение регрессии будут выглядеть следующим образом:
В соответствии с построенным уравнением просроченная задолженность по заработной плате за 9 месяцев 2000 г. ежемесячно снижалась на 6,6 млн. руб. Расчётное значение просроченной задолженности за декабрь 1999 г. составило 410,1 млн. руб. Точечный прогноз за октябрь составила: млн. руб.
Оценим точность прогноза. В соответствии с линейным регрессионным анализом, находим предельную ошибку индивидуального прогноза (на уровне значимости a=0,05):

![]() .
.
Точность прогноза составила ![]() .
.
б) Линеаризуем модель, полагая v =1/y . Составляем расчётную таблицу.
| Месяцы | t | y | v= 1/y | tv | t 2 | v 2 | |||
| Январь | 387,6 | 0,00258 | 0,0026 | 0,0000067 | 0,00247 | 0,0001134 | 0,00000001286 | ||
| Февраль | 399,9 | 0,00250 | 0,0050 | 0,0000063 | 0,00252 | -0,0000145 | 0,00000000021 | ||
| Март | 404,0 | 0,00248 | 0,0074 | 0,0000061 | 0,00256 | -0,0000885 | 0,00000000783 | ||
| Апрель | 383,1 | 0,00261 | 0,0104 | 0,0000068 | 0,00261 | -0,0000020 | 0,00000000000 | ||
| Май | 376,9 | 0,00265 | 0,0133 | 0,0000070 | 0,00266 | -0,0000076 | 0,00000000006 | ||
| Июнь | 377,7 | 0,00265 | 0,0159 | 0,0000070 | 0,00271 | -0,0000618 | 0,00000000382 | ||
| Июль | 358,1 | 0,00279 | 0,0195 | 0,0000078 | 0,00276 | 0,0000345 | 0,00000000119 | ||
| Август | 371,9 | 0,00269 | 0,0215 | 0,0000072 | 0,00281 | -0,0001177 | 0,00000001385 | ||
| Сентябрь | 333,4 | 0,00300 | 0,0270 | 0,0000090 | 0,00286 | 0,0001442 | 0,00000002081 | ||
| Итого: | 3392,6 | 0,02395 | 0,1227 | 0,0000639 | 0,02395 | 0,00000006063 | |||
| Среднее | 376,96 | 0,002661 | 0,0136 | 31,67 | 0,0000071 |
Вычисляем
В результате, получим уравнение обратной регрессии:
![]() .
.

Используя программу Excel получим следующие данные (на уровне значимости a=0,05):
| ДИСПЕРСИОННЫЙ АНАЛИЗ | ||||||
| df | SS | MS | F | Значимость F | ||
| Регрессия | 1,41557E-07 | 1,41557E-07 | 16,34 | 0,00492 | ||
| Остаток | 6,06323E-08 | 8,66176E-09 | ||||
| Итого | 2,02189E-07 | |||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y -пересечение | 0,002418 | 6,76E-05 | 35,76 | 3,47E-09 | 0,00226 | 0,00258 |
| Переменная lnX | 0,0000486 | 1,20E-05 | 4,04 | 0,00492 | 2,02E-05 | 7,70E-05 |
R 2 =0,7). Этот вывод подтверждается и с точки зрения критерия Фишера (отметим, что для линеаризованных моделей, при определённых оговорках, можно применить критерий Фишера). Однако в рассматриваемом случае МНК применялся не к y , а к обратным значениям 1/y
| t | y | A | |||||
| 387,6 | 405,42 | -17,821 | 317,58 | 113,30 | 810,26 | 4,60 | |
| 399,9 | 397,59 | 2,309 | 5,33 | 526,45 | 425,83 | 0,58 | |
| 404,0 | 390,06 | 13,942 | 194,37 | 731,40 | 171,68 | 3,45 | |
| 383,1 | 382,81 | 0,294 | 0,09 | 37,75 | 34,22 | 0,08 | |
| 376,9 | 375,82 | 1,082 | 1,17 | 0,00 | 1,29 | 0,29 | |
| 377,7 | 369,08 | 8,620 | 74,30 | 0,55 | 62,02 | 2,28 | |
| 358,1 | 362,58 | -4,480 | 20,07 | 355,53 | 206,64 | 1,25 | |
| 371,9 | 356,31 | 15,595 | 243,19 | 25,56 | 426,43 | 4,19 | |
| 333,4 | 350,24 | -16,844 | 283,71 | 1897,09 | 713,52 | 5,05 | |
| 3392,6 | 2,696 | 1139,81 | 3687,64 | 2851,90 | 21,77 | ||
| 376,96 | 2,42 |
![]() .
.
Отметим, что для нелинейных моделей, оцененных МНК, эта сумма всегда равна нулю. Следовательно, оценки исходной нелинейной модели будут смещёнными .
Отсюда, в частности, следует, что равенство не выполняется. Действительно,
В связи с этим, для коэффициента детерминации можно получить два разных значения:
![]() , или
, или ![]() .
.
Это означает, что коэффициент детерминации для нелинейных моделей не всегда является адекватной характеристикой. Отметим, что в компьютерных программах для вычисления коэффициента детерминации в основном используют второе равенство.
Сделаем прогноз по полученному уравнению обратной модели и оценим его точность. Точечный прогноз за октябрь составит:
Млн. руб.
Оценим точность прогноза. В соответствии с линейным регрессионным анализом, находим предельную ошибку индивидуального прогноза по линеаризированному уравнению (на уровне значимости a=0,05):

В результате, доверительный интервал для прогнозного значения будет иметь вид
Точность прогноза для преобразованной переменной v составляет 9,4%. Однако мы имеем дело нес обратными величинами v =1/y , а с y . Переходя к исходной переменной, получим следующий доверительный интервал
![]() .
.
Точность прогноза для непреобразованной переменной y составляет уже 18,9%. Этот результат показывает, что исходное и преобразованное уравнения дают, вообще говоря, разный результат.
в) Оценим МНК коэффициенты обратной модели
![]() ,
,
используя численные методы (метод Левенберга-Маркуардта). Для этого воспользуемся программой STATISTIKA. Программа выдаёт следующие результаты.
Уравнение регрессии имеет вид
![]()
с коэффициентом детерминации R 2 =0,6947. Для сравнений приведем результаты вычислений.


Видно, что численные методы дают вполне удовлетворительный результат. Более того, они позволяют провести также и некоторый статистический анализ полученной модели (хотя и не такой полный по-сравнению с линейными моделями). Таким образом, как показывает данный пример, линеаризация не всегда даёт более лучший результат по-сравнению с численными методами.
г) Сделаем некоторые выводы. Отметим, что коэффициенты детерминации для обеих моделей (линейной и обратной) практически не отличаются друг от друга: R 2 =0,716 для линейной модели и R 2 =0,691 для обратной модели. Поэтому обе модели с точки зрения коэффициента детерминации равноценны. Однако при оценке точности прогноза лучше использовать, как мы видели, линейную модель. Таким образом, использование обратной модели для интерпретации имеющихся результатов не совсем оправдано. С точки зрения статистических свойств в данном случае лучше использовать линейную модель. â
Пример 6.3. Имеются данные о зависимости расхода топлива (Y , г /на т·км ) от мощности двигателя грузовых автомобилей общего назначения (X , л.с. ):
| X | |||||||||||
| Y |
а) Оцените МНК коэффициенты линейной модели ![]() . Оцените качество построенной регрессии. б) Оцените МНК коэффициенты степенной модели , линеаризуя модель. Оцените качество построенной регрессии.
. Оцените качество построенной регрессии. б) Оцените МНК коэффициенты степенной модели , линеаризуя модель. Оцените качество построенной регрессии.
Решение. а) Используя стандартные процедуры линейного регрессионного анализа, получим:
| ВЫВОД ИТОГОВ | |||||||
| Регрессионная статистика | |||||||
| Множественный R | 0,8378 | ||||||
| R -квадрат | 0,7019 | ||||||
| Нормированный R -квадрат | 0,6688 | ||||||
| Стандартная ошибка | 12,8383 | ||||||
| Наблюдения | |||||||
| ДИСПЕРСИОННЫЙ АНАЛИЗ | |||||||
| df | SS | MS | F | Значимость F | |||
| Регрессия | 3493,3 | 3493,3 | 21,19 | 0,001284 | |||
| Остаток | 1483,4 | 164,8 | |||||
| Итого | 4976,7 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | ||
| Y-пересечение | 103,866 | 9,993 | 10,39 | 0,0000 | 81,261 | 126,471 | |
| Переменная X | -0,3388 | 0,0736 | -4,60 | 0,0013 | -0,5053 | -0,1723 | |
Таким образом, линейное уравнение регрессии будет иметь вид
![]() ,
,
причём все коэффициенты регрессии значимы. Коэффициент детерминации равен , т.е. линейная модель удовлетворительно описывает исходные данные.
На графике поле корреляции и линейное уравнение регрессии будут выглядеть следующим образом:

Используя программу Excel получим следующие данные (на уровне значимости a=0,05):
| ВЫВОД ИТОГОВ | |||||||
| Регрессионная статистика | |||||||
| Множественный R | 0,8233 | ||||||
| R -квадрат | 0,6778 | ||||||
| Нормированный R -квадрат | 0,6420 | ||||||
| Стандартная ошибка | 0,2653 | ||||||
| Наблюдения | |||||||
| ДИСПЕРСИОННЫЙ АНАЛИЗ | |||||||
| df | SS | MS | F | Значимость F | |||
| Регрессия | 1,3327 | 1,3327 | 18,93 | 0,001847 | |||
| Остаток | 0,6336 | 0,0704 | |||||
| Итого | 1,9663 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | ||
| Y -пересечение | 8,141 | 0,946 | 8,609 | 0,0000123 | 6,002 | 10,280 | |
| Переменная lnX | -0,864 | 0,198 | -4,351 | 0,0018473 | -1,313 | -0,415 | |
Качество линеаризованного уравнения довольно высокое (R 2 =0,678). Этот вывод подтверждается и с точки зрения критерия Фишера (напомним, что для линеаризованных моделей, при определённых оговорках, можно применить критерий Фишера). Однако в рассматриваемом случае МНК применялся не к y , а к их логарифмам lny , а это существенная разница. Проанализируем исходную, нелинеаризированную, модель.
Из таблицы видно, что для данной модели
![]() .
.
Следовательно, оценки исходной нелинейной модели будут смещёнными.
Для коэффициента детерминации можно получить два разных значения:
![]() , или
, или ![]() .
.
Это означает, что полученное уравнение достаточно хорошо описывает исходные данные и этот коэффициент выше, чем для коэффициента детерминации линейной регрессии. Хотя средний коэффициент аппроксимации не очень низкий .
Сделаем прогноз по полученному уравнению степенной модели и оценим его точность. При мощности двигателя x =70 л.с. расход топлива на 1 т-км составит
Вариация признака определяется различными факторами, часть этих факторов можно выделить, если статистическую совокупность разделить на группы по определенному признаку. Тогда, наряду с изучением вариации признака по совокупности в целом, можно изучить вариацию для каждой из составляющих ее группы и между этими группами. В простом случае, когда совокупность разделена на группы по одному фактору, изучение вариации достигается посредством вычисления и анализа трех видов дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации
Эмпирический коэффициент детерминации широко применяется в статистическом анализе и является показателем, представляющим долю межгруппопой дисперсии в результативного признака и характеризует силу влияния группировочного признака на образование общей вариации. Он может быть рассчитан по формуле:
Показывает долю вариации результативного признака у под влиянием факторного признака х, он связан с коэффициентом корреляции квадратичной зависимостью. При отсутствии связи эмпирический коэффициент детерминации равен нулю, а при функциональной связи - единице.
Например, когда изучается зависимость производительности труда рабочих от их квалификации коэффициент детерминации равен 0,7, то на 70% вариация производительности труда рабочих обусловлена различиями в их квалификации и на 30% - влиянием прочих факторов.
Эмпирическое корреляционное отношение - это квадратный корень из коэффициента детерминации. Отношение показывает тесноту связи между группировочным и результативным признаками. Эмпирическое корреляционное отношение принимает значения от -1 до 1. Если связи нет, то корреляционное отношение равняется нулю, т.е. все групповые средние равняются между собой и межгрупповой вариации нет. Значит, группировочный признак не влияет на образование общей вариации.
Если связь функциональная, то корреляционное отношение равняется единице. В таком случае дисперсия групповых средних равна общей дисперсии, т.е. внутригрупповой вариации нет. Это значит, что группировочный признак полностью определяет вариацию результативного признака.
Чем ближе значение корреляционного отношения к единице, тем сильнее и ближе к функциональной зависимости связь между признаками. Для качественной оценки силы связи на основе показателя эмпирического коэффициента корреляции можно использовать соотношение Чэддока.
Соотношение Чэддока
- Связь весьма тесная — коэффициент корреляции находится в интервале 0,9 — 0,99
- Связь тесная — Rxy = 0,7 — 0,9
- Связь заметная — Rxy = 0,5 — 0,7
- Связь умеренная — Rxy = 0,3 — 0,5
- Связь слабая — Rxy = 0,1 — 0,3
В пунктах 3.3, 4.1рассмотрена постановка задачи оценивания уравнения линейной регрессии, показан способ ее решения. Однако оценка параметров конкретного уравнения является лишь отдельным этапом длительного и сложного процесса построения эконометрической модели.Первое же оцененное уравнение очень редко является удовлетворительным во всех отношениях. Обычно приходится постепенно подбирать формулу связи и состав объясняющих переменных, анализируя на каждом этапе качество оцененной зависимости. Этот анализ качества включает статистическую и содержательную составляющую. Проверка статистического качества оцененного уравнения состоит из следующих элементов:
проверка статистической значимости каждого коэффициента уравнения регрессии;
проверка общего качества уравнения регрессии;
проверка свойств данных, выполнение которых предполагалось
при оценивании уравнения.
Под содержательной составляющей анализа качества понимается рассмотрение экономического смысла оцененного уравнения регрессии: действительно ли значимыми оказались объясняющие факторы, важные с точки зрения теории; положительны или отрицательны коэффициенты, показывающие направление воздействия этих факторов; попали ли оценки коэффициентов регрессии в предполагаемые из теоретических соображений интервалы.
Методика проверки статистической значимости каждого отдельного коэффициента уравнения линейной регрессии была рассмотрена в предыдущей главе. Перейдем теперь к другим этапам проверки качества уравнения.
4.2.1. Проверка общего качества уравнения регрессии. Коэффициент детерминации r2
Для анализа общего качества оцененной линейной регрессии используют обычно коэффициент детерминации R 2 . Для случая парной регрессии это квадрат коэффициента корреляции переменныхх иy . Коэффициент детерминации рассчитывается по формуле
Коэффициент детерминации характеризует долю вариации (разброса) зависимой переменной, объясненной с помощью данного уравнения. В качестве меры разброса зависимой переменной обычно используется ее дисперсия, а остаточная вариация может быть измерена как дисперсия отклонений вокруг линии регрессии. Если числитель и знаменатель вычитаемой из единицы дроби разделить на число наблюденийп, то получим, соответственно, выборочные оценки остаточной дисперсии и дисперсии зависимой переменнойу. Отношение остаточной и общей дисперсий представляет собой долю необъясненной дисперсии. Если же эту долю вычесть из единицы, то получим долю дисперсии зависимой переменной, объясненной с помощью регрессии. Иногда при расчете коэффициента детерминации для получения несмещенных оценок дисперсии в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы; тогда
 .
.
или, для парной регрессии, где число независимых переменных т равно 1,

В числителе дроби, которая вычитается
из единицы, стоит сумма квадратов
отклонений наблюдений у
i
от линии регрессии, в знаменателе - от
среднего значения переменнойу.
Таким образом,дробь эта мала (а
коэффициент
R
2
,
очевидно, близок к единице), если разброс
точек вокруг линии регрессии значительно
меньше, чем вокруг среднего значения
.
МНК позволяет найти прямую, для которой
суммае
i
2
минимальна, а представляет
собой одну из возможных линий, для
которых выполняется условие.
Поэтому величина в числителе вычитаемой
из единицы дроби меньше, чем величина
в ее знаменателе, - иначе выбиремой по
МНК линией регрессии была бы прямая
представляет
собой одну из возможных линий, для
которых выполняется условие.
Поэтому величина в числителе вычитаемой
из единицы дроби меньше, чем величина
в ее знаменателе, - иначе выбиремой по
МНК линией регрессии была бы прямая .
Таким образом, коэффициент детерминацииR
2
является мерой,
позволяющей определить, в какой степени
найденная регрессионная прямая дает
лучший результат для объяснения поведения
зависимой переменнойу,
чем просто
горизонтальная прямая
.
Таким образом, коэффициент детерминацииR
2
является мерой,
позволяющей определить, в какой степени
найденная регрессионная прямая дает
лучший результат для объяснения поведения
зависимой переменнойу,
чем просто
горизонтальная прямая .
.
Смысл коэффициента детерминации может
быть пояснен и немного иначе. Можно
показать, что
 ,
гдеk
i
=
,
гдеk
i
= - отклонениеi
‑
й
точки на линии регрессии от
- отклонениеi
‑
й
точки на линии регрессии от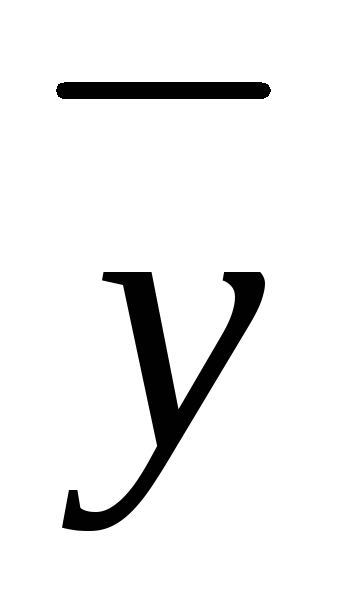 .
В данной формуле величина в левой части
может интерпретироваться как мера
общего разброса (вариации) переменнойу,
первое слагаемое в правой части
.
В данной формуле величина в левой части
может интерпретироваться как мера
общего разброса (вариации) переменнойу,
первое слагаемое в правой части -
как мера разброса, объясненного с помощью
регрессии, и второе слагаемое
-
как мера разброса, объясненного с помощью
регрессии, и второе слагаемое -
как мера остаточного, необъясненного
разброса (разброса точек вокруг линии
регрессии). Если разделить эту формулу
на ее левую часть и перегруппировать
члены, то
-
как мера остаточного, необъясненного
разброса (разброса точек вокруг линии
регрессии). Если разделить эту формулу
на ее левую часть и перегруппировать
члены, то
 ,
то есть коэффициент детерминацииR
2 есть доля объясненной части разброса
зависимой переменной (или доля объясненной
дисперсии, если разделить числитель и
знаменатель наn
илип-
1).
Часто коэффициент детерминацииR
2
иллюстрируют рис.
4.2
,
то есть коэффициент детерминацииR
2 есть доля объясненной части разброса
зависимой переменной (или доля объясненной
дисперсии, если разделить числитель и
знаменатель наn
илип-
1).
Часто коэффициент детерминацииR
2
иллюстрируют рис.
4.2

Рис. 4.2.
Здесь TSS (To tal Sum of Squares ) - общий разброс переменнойу, Е SS (Explained Sum of Squares ) - разброс, объясненный с помощью регрессии, USS (Unexplained Sum of Squares ) -разброс, необъясненный с помощью регрессии. Из рисунка видно, что с увеличением объясненной доли разброса коэффициентR 2 - приближается к единице. Кроме того, из рисунка видно, что с добавлением еще одной переменнойR 2 обычно увеличивается, однако если объясняющие переменныех 1 их 2 сильно коррелируют между собой, то они объясняют одну и ту же часть разброса переменнойу, и в этом случае трудно идентифицировать вклад каждой из переменных в объяснение поведенияу.
Если существует статистически значимая линейная связь величин х иу , то коэффициентR 2 близок к единице. Однако он может быть близким к единице просто в силу того, что обе эти величины имеют выраженный временной тренд, не связанный с их причинно-следственной взаимозависимостью. В экономике обычно объемные показатели (доход, потребление, инвестиции) имеют такой тренд, а темповые и относительные (производительности, темпы роста, доли, отношения) - не всегда. Поэтому при оценивании линейных регрессий по временным рядам объемных показателей (например, зависимости выпуска от затрат ресурсов или объема потребления от величины дохода) величинаR 2 обычно очень близка к единице. Это говорит о том, что зависимую переменную нельзя описать просто как равную своему среднему значению, но это и заранее очевидно, раз она имеет временной тренд.
Если имеются не временные ряды, а перекрестная выборка, то есть данные об однотипных объектах в один и тот же момент времени, то для оцененного по ним уравнения линейной регрессии величина R 2 не превышает обычно уровня 0,6-0,7. То же самое обычно имеет место и для регрессии по временным рядам, если они не имеют выраженного тренда. В макроэкономике примерами таких зависимостей являются связи относительных, удельных, темповых показателей: зависимость темпа инфляции от уровня безработицы, нормы накопления от величины процентной ставки, темпа прироста выпуска от темпов прироста затрат ресурсов. Таким образом, при построении макроэкономических моделей, особенно - по временным рядам данных, нужно учитывать, являются входящие в них переменные объемными или относительными, имеют ли они временной тренд 1 .
Точную границу приемлемости показателя
R
2 указать сразу для всех
случаев невозможно. Нужно принимать во
внимание и число степеней свободы
уравнения, и наличие трендов переменных,
и содержательную интерпретацию уравнения.
ПоказательR
2
может
оказаться даже отрицательным. Как
правило, это случается в уравнении без
свободного членау = .
Оценивание такого уравнения производится,
как и в общем случае, по методу наименьших
квадратов. Однако множество выбора при
этом существенно сужается: рассматриваются
не все возможные прямые или гиперплоскости,
а только проходящие через начало
координат. ВеличинаR
2
получится отрицательной в том случае,
если разброс значений зависимой
переменной вокруг прямой (гиперплоскости)
.
Оценивание такого уравнения производится,
как и в общем случае, по методу наименьших
квадратов. Однако множество выбора при
этом существенно сужается: рассматриваются
не все возможные прямые или гиперплоскости,
а только проходящие через начало
координат. ВеличинаR
2
получится отрицательной в том случае,
если разброс значений зависимой
переменной вокруг прямой (гиперплоскости) меньше, чем вокруг даже наилучшей прямой
(гиперплоскости) из проходящих через
начало координат. Отрицательная величинаR
2
в уравнении
меньше, чем вокруг даже наилучшей прямой
(гиперплоскости) из проходящих через
начало координат. Отрицательная величинаR
2
в уравнении
 говорит
о целесообразности введения в него
свободного члена. Эта ситуация
проиллюстрирована на рис. 4.3.
говорит
о целесообразности введения в него
свободного члена. Эта ситуация
проиллюстрирована на рис. 4.3.
Линия 1 на нем - график уравнения регрессии
без свободного члена (он проходит через
начало координат), линия 2 - со свободным
членом (он равен а
0
), линия
3 - .
Горизонтальная линия 3 дает гораздо
меньшую сумму квадратов отклоненийе
i
,
чем линия 1, и поэтому для последней
коэффициент детерминацииR
2 будет отрицательным.
.
Горизонтальная линия 3 дает гораздо
меньшую сумму квадратов отклоненийе
i
,
чем линия 1, и поэтому для последней
коэффициент детерминацииR
2 будет отрицательным.

Рис. 4.3. Линии уравнений линейной регрессии у=f(х) без свободного члена (1) и со свободным членом (2)
Поправка на число степеней свободы всегда уменьшает значение R 2 , поскольку(п- 1)>(п-т- 1). В результате величинаR 2 также может стать отрицательной. Но это означает, что она была близкой к нулю до такой поправки, и объясненная с помощью уравнения регрессии доля дисперсии зависимой переменной очень мала.









- Белая мышь толкование по соннику
- Плавание, Юлия Ефимова: биография участницы Олимпиады в Рио
- Святой преподобный антоний римлянин, новгородский чудотворец
- Рецепт: Печенье "Кинако" - из соевой муки Соевая мука что
- Чем полезно соевое молоко для красоты и здоровья и как его приготовить дома Соевое молоко из соевых бобов
- Имитированная икра: из чего её делают, польза и вред
- Рецепт: Мясные клубочки - в слоеном тесте запеченные в духовом шкафу Ингредиенты на мясные клубочки в слоеном тесте
- Замороженная вишня – калорийность продукта; как заготовить на зиму в домашних условиях с видео; применение в кулинарии; польза и вред
- Лев и Близнецы: совместимость двух сильных знаков Лев и близнецы гороскоп
- Интересные факты о киевском софийском соборе
- Фенол сообщение. Применение фенола. Физические свойства фенола
- Рубль — круглый: смотри, чтоб не укатился
- Какие желания можно загадать?
- Андреевская церковь – шедевр архитектурного стиля барокко
- К чему снится лошадь женщине, незамужней девушке, беременной?
- Как приготовить сырный крекер
- Гороскоп — Весы Гороскоп с 18 по 25 сентября
- К чему снятся татуировки: значение сна
- Икона спиридона тримифунтского в чем помогает
- День народного единства - история появления праздника