Хи критическое. Как интерпретировать значение критерия хи-квадрат Пирсона
Хи-квадрат Пирсона - это наиболее простой критерий проверки значимости связи между двумя категоризованными переменными. Критерий Пирсона основывается на том, что в двувходовой таблице ожидаемые частоты при гипотезе "между переменными нет зависимости" можно вычислить непосредственно. Представьте, что 20 мужчин и 20 женщин опрошены относительно выбора газированной воды (марка A или марка B ). Если между предпочтением и полом нет связи, то естественно ожидать равного выбора марки A и марки B для каждого пола.
Значение статистики хи-квадрат и ее уровень значимости зависит от общего числа наблюдений и количества ячеек в таблице. В соответствии с принципами, обсуждаемыми в разделе , относительно малые отклонения наблюдаемых частот от ожидаемых будет доказывать значимость, если число наблюдений велико.
Имеется только одно существенное ограничение использования критерия хи-квадрат (кроме очевидного предположения о случайном выборе наблюдений), которое состоит в том, что ожидаемые частоты не должны быть очень малы. Это связано с тем, что критерий хи-квадрат по своей природе проверяет вероятности в каждой ячейке; и если ожидаемые частоты в ячейках, становятся, маленькими, например, меньше 5, то эти вероятности нельзя оценить с достаточной точностью с помощью имеющихся частот. Дальнейшие обсуждения см. в работах Everitt (1977), Hays (1988) или Kendall and Stuart (1979).
Критерий хи-квадрат (метод максимального правдоподобия). Максимум правдоподобия хи-квадрат предназначен для проверки той же самой гипотезы относительно связей в таблицах сопряженности, что и критерий хи-квадрат Пирсона. Однако его вычисление основано на методе максимального правдоподобия. На практике статистика МП хи-квадрат очень близка по величине к обычной статистике Пирсона хи-квадрат . Подробнее об этой статистике можно прочитать в работах Bishop, Fienberg, and Holland (1975) или Fienberg (1977). В разделе Логлинейный анализ эта статистика обсуждается подробнее.
Поправка Йетса. Аппроксимация статистики хи-квадрат для таблиц 2x2 с малыми числом наблюдений в ячейках может быть улучшена уменьшением абсолютного значения разностей между ожидаемыми и наблюдаемыми частотами на величину 0.5 перед возведением в квадрат (так называемая поправка Йетса ). Поправка Йетса, делающая оценку более умеренной, обычно применяется в тех случаях, когда таблицы содержат только малые частоты, например, когда некоторые ожидаемые частоты становятся меньше 10 (дальнейшее обсуждение см. в Conover, 1974; Everitt, 1977; Hays, 1988; Kendall and Stuart, 1979 и Mantel, 1974).
Точный критерий Фишера. Этот критерий применим только для таблиц 2x2. Критерий основан на следующем рассуждении. Даны маргинальные частоты в таблице, предположим, что обе табулированные переменные независимы. Зададимся вопросом: какова вероятность получения наблюдаемых в таблице частот, исходя из заданных маргинальных? Оказывается, эта вероятность вычисляется точно подсчетом всех таблиц, которые можно построить, исходя из маргинальных. Таким образом, критерий Фишера вычисляет точную вероятность появления наблюдаемых частот при нулевой гипотезе (отсутствие связи между табулированными переменными). В таблице результатов приводятся как односторонние, так и двусторонние уровни.
Хи-квадрат Макнемара. Этот критерий применяется, когда частоты в таблице 2x2 представляют зависимые выборки. Например, наблюдения одних и тех же индивидуумов до и после эксперимента. В частности, вы можете подсчитывать число студентов, имеющих минимальные успехи по математике в начале и в конце семестра или предпочтение одних и тех же респондентов до и после рекламы. Вычисляются два значения хи-квадрат : A/D и B/C . A/D хи-квадрат проверяет гипотезу о том, что частоты в ячейках A и D (верхняя левая, нижняя правая) одинаковы. B/C хи-квадрат проверяет гипотезу о равенстве частот в ячейках B и C (верхняя правая, нижняя левая).
Коэффициент Фи. Фи-квадрат представляет собой меру связи между двумя переменными в таблице 2x2. Его значения изменяются от 0 (нет зависимости между переменными; хи-квадрат = 0.0 ) до 1 (абсолютная зависимость между двумя факторами в таблице). Подробности см. в Castellan and Siegel (1988, стр. 232).
Тетрахорическая корреляция. Эта статистика вычисляется (и применяется) только для таблиц сопряженности 2x2. Если таблица 2x2 может рассматриваться как результат (искусственного) разбиения значений двух непрерывных переменных на два класса, то коэффициент тетрахорической корреляции позволяет оценить зависимость между двумя этими переменными.
Коэффициент сопряженности. Коэффициент сопряженности представляет собой основанную на статистике хи-квадрат меру связи признаков в таблице сопряженности (предложенную Пирсоном). Преимущество этого коэффициента перед обычной статистикой хи-квадрат в том, что он легче интерпретируется, т.к. диапазон его изменения находится в интервале от 0 до 1 (где 0 соответствует случаю независимости признаков в таблице, а увеличение коэффициента показывает увеличение степени связи). Недостаток коэффициента сопряженности в том, что его максимальное значение "зависит" от размера таблицы. Этот коэффициент может достигать значения 1 только, если число классов не ограничено (см. Siegel, 1956, стр. 201).
Интерпретация мер связи. Существенный недостаток мер связи (рассмотренных выше) связан с трудностью их интерпретации в обычных терминах вероятности или "доли объясненной вариации", как в случае коэффициента корреляции r Пирсона (см. Корреляции). Поэтому не существует одной общепринятой меры или коэффициента связи.
Статистики, основанные на рангах. Во многих задачах, возникающих на практике, мы имеем измерения лишь в порядковой шкале (см. Элементарные понятия статистики ). Особенно это относится к измерениям в области психологии, социологии и других дисциплинах, связанных с изучением человека. Предположим, вы опросили некоторое множество респондентов с целью выяснения их отношение к некоторым видам спорта. Вы представляете измерения в шкале со следующими позициями: (1) всегда , (2) обычно , (3) иногда и (4) никогда . Очевидно, что ответ иногда интересуюсь показывает меньший интерес респондента, чем ответ обычно интересуюсь и т.д. Таким образом, можно упорядочить (ранжировать) степень интереса респондентов. Это типичный пример порядковой шкалы. Для переменных, измеренных в порядковой шкале, имеются свои типы корреляции, позволяющие оценить зависимости.
R Спирмена. Статистику R Спирмена можно интерпретировать так же, как и корреляцию Пирсона (r Пирсона) в терминах объясненной доли дисперсии (имея, однако, в виду, что статистика Спирмена вычислена по рангам). Предполагается, что переменные измерены как минимум в порядковой шкале. Всестороннее обсуждение ранговой корреляции Спирмена, ее мощности и эффективности можно найти, например, в книгах Gibbons (1985), Hays (1981), McNemar (1969), Siegel (1956), Siegel and Castellan (1988), Kendall (1948), Olds (1949) и Hotelling and Pabst (1936).
Тау Кендалла. Статистика тау Кендалла эквивалентна R Спирмена при выполнении некоторых основных предположений. Также эквивалентны их мощности. Однако обычно значения R Спирмена и тау Кендалла различны, потому что они отличаются как своей внутренней логикой, так и способом вычисления. В работе Siegel and Castellan (1988) авторы выразили соотношение между этими двумя статистиками следующим неравенством:
1 < = 3 * Тау Кендалла - 2 * R Спирмена < = 1
Более важно то, что статистики Кендалла тау и Спирмена R имеют различную интерпретацию: в то время как статистика R Спирмена может рассматриваться как прямой аналог статистики r Пирсона, вычисленный по рангам, статистика Кендалла тау скорее основана на вероятности . Более точно, проверяется, что имеется различие между вероятностью того, что наблюдаемые данные расположены в том же самом порядке для двух величин и вероятностью того, что они расположены в другом порядке. Kendall (1948, 1975), Everitt (1977), и Siegel and Castellan (1988) очень подробно обсуждают тау Кендалла. Обычно вычисляется два варианта статистики тау Кендалла: tau b и tau c . Эти меры различаются только способом обработки совпадающих рангов. В большинстве случаев их значения довольно похожи. Если возникают различия, то, по-видимому, самый безопасный способ - рассматривать наименьшее из двух значений.
Коэффициент d Соммера: d(X|Y), d(Y|X). Статистика d Соммера представляет собой несимметричную меру связи между двумя переменными. Эта статистика близка к tau b (см. Siegel and Castellan, 1988, стр. 303-310).
Гамма-статистика. Если в данных имеется много совпадающих значений, статистика гамма предпочтительнее R Спирмена или тау Кендалла. С точки зрения основных предположений, статистика гамма эквивалентна статистике R Спирмена или тау Кендалла. Ее интерпретация и вычисления более похожи на статистику тау Кендалла, чем на статистику R Спирмена. Говоря кратко, гамма представляет собой также вероятность ; точнее, разность между вероятностью того, что ранговый порядок двух переменных совпадает, минус вероятность того, что он не совпадает, деленную на единицу минус вероятность совпадений. Таким образом, статистика гамма в основном эквивалентна тау Кендалла, за исключением того, что совпадения явно учитываются в нормировке. Подробное обсуждение статистики гамма можно найти у Goodman and Kruskal (1954, 1959, 1963, 1972), Siegel (1956) и Siegel and Castellan (1988).
Коэффициенты неопределенности. Эти коэффициенты измеряют информационную связь между факторами (строками и столбцами таблицы). Понятие информационной зависимости берет начало в теоретико-информационном подходе к анализу таблиц частот, можно обратиться к соответствующим руководствам для разъяснения этого вопроса (см. Kullback, 1959; Ku and Kullback, 1968; Ku, Varner, and Kullback, 1971; см. также Bishop, Fienberg, and Holland, 1975, стр. 344-348). Статистика S (Y,X ) является симметричной и измеряет количество информации в переменной Y относительно переменной X или в переменной X относительно переменной Y . Статистики S(X|Y) и S(Y|X) выражают направленную зависимость.
Многомерные отклики и дихотомии. Переменные типа многомерных откликов и многомерных дихотомий возникают в ситуациях, когда исследователя интересуют не только "простые" частоты событий, но также некоторые (часто неструктурированные) качественные свойства этих событий. Природу многомерных переменных (факторов) лучше всего понять на примерах.
- · Многомерные отклики
- · Многомерные дихотомии
- · Кросстабуляция многомерных откликов и дихотомий
- · Парная кросстабуляция переменных с многомерными откликами
- · Заключительный комментарий
Многомерные отклики. Представьте, что в процессе большого маркетингового исследования, вы попросили покупателей назвать 3 лучших, с их точки зрения, безалкогольных напитка. Обычный вопрос может выглядеть следующим образом.
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F (x ) и эмпирическим распределением F * п (x ) , которая приближенно подчиняется закону распределения χ 2 . Гипотеза Н 0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов M . Наблюдаемая частота попаданий в i - й разряд n i . В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i -й разряд составляет F i . Разность между наблюдаемой и ожидаемой частотой составит величину (n i – F i ). Для нахождения общей степени расхождения между F (x ) и F * п (x ) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
Величина χ 2 при неограниченном увеличении n имеет χ 2 -распределение (асимптотически распределена как χ 2). Это распределение зависит от числа степеней свободы k , т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся M –1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются S параметров распределения, то число степеней свободы составит k = M – S –1.
Область принятия гипотезы Н 0 определяется условием χ 2 < χ 2 (k ; a ) , где χ 2 (k ; a ) – критическая точка χ2-распределения с уровнем значимости a . Вероятность ошибки первого рода равна a , вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n >200, допускается применение при n >40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Алгоритм проверки по критерию
1. Построить гистограмму равновероятностным способом.
2. По виду гистограммы выдвинуть гипотезу
H 0: f (x ) = f 0 (x ),
H 1: f (x ) ¹ f 0 (x ),
где f 0 (x ) - плотность вероятности гипотетического закона распределения (например, равномерного, экспоненциального, нормального).
Замечание . Гипотезу об экспоненциальном законе распределения можно выдвигать в том случае, если все числа в выборке положительные.
3. Вычислить значение критерия по формуле
 ,
,
где  частота
попадания вi
-тый интервал;
частота
попадания вi
-тый интервал;
p i - теоретическая вероятность попадания случайной величины вi - тый интервал при условии, что гипотезаH 0 верна.
Формулы для расчета p i в случае экспоненциального, равномерного и нормального законов соответственно равны.
Экспоненциальный закон
 . (3.8)
. (3.8)
При этом A 1 = 0, B m = +¥.
Равномерный закон
Нормальный закон
 . (3.10)
. (3.10)
При этом A 1 = -¥, B M = +¥.
Замечания . После вычисления всех вероятностей p i проверить, выполняется ли контрольное соотношение

Функция Ф(х )- нечетная. Ф(+¥) = 1.
4.
Из таблицы " Хи-квадрат" Приложения
выбирается значение
 ,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
k = M - 1 - S .
Здесь S - число параметров, от которых зависит выбранный гипотезой H 0 закон распределения. Значения S для равномерного закона равно 2, для экспоненциального - 1, для нормального - 2.
5.
Если
 ,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
Пример3 . 1. С помощью критерия c 2 выдвинуть и проверить гипотезу о законе распределения случайной величины X , вариационный ряд, интервальные таблицы и гистограммы распределения которой приведены в примере 1.2. Уровень значимости a равен 0,05.
Решение . По виду гистограмм выдвигаем гипотезу о том, что случайная величина X распределена по нормальному закону:
H 0: f (x ) = N (m , s);
H 1: f (x ) ¹ N (m , s).
Значение критерия вычисляем по формуле:
 (3.11)
(3.11)
Как отмечалось выше, при проверке гипотезы предпочтительнее использовать равновероятностную гистограмму. В этом случае

Теоретические вероятности p i рассчитываем по формуле (3.10). При этом полагаем, что

p 1 = 0,5(Ф((-4,5245+1,7)/1,98)-Ф((-¥+1,7)/1,98)) = 0,5(Ф(-1,427)-Ф(-¥)) =
0,5(-0,845+1) = 0,078.
p 2 = 0,5(Ф((-3,8865+1,7)/1,98)-Ф((-4,5245+1,7)/1,98)) =
0,5(Ф(-1,104)+0,845) = 0,5(-0,729+0,845) = 0,058.
p 3 = 0,094; p 4 = 0,135; p 5 = 0,118; p 6 = 0,097; p 7 = 0,073; p 8 = 0,059; p 9 = 0,174;
p 10 = 0,5(Ф((+¥+1,7)/1,98)-Ф((0,6932+1,7)/1,98)) = 0,114.
После этого проверяем выполнение контрольного соотношения

100 × (0,0062 + 0,0304 + 0,0004 + 0,0091 + 0,0028 + 0,0001 + 0,0100 +
0,0285 + 0,0315 + 0,0017) = 100 × 0,1207 = 12,07.
После этого из таблицы "Хи - квадрат" выбираем критическое значение
 .
.
Так
как
 то гипотезаH
0
принимается (нет основания ее отклонить).
то гипотезаH
0
принимается (нет основания ее отклонить).
Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная
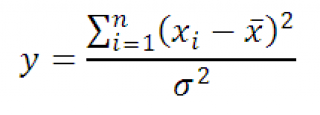
Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:

Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).
Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна
где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).
Распределение вероятных значений случайной величины χ2 непрерывно и ассиметрично. Оно зависит от числа степеней свободы (n) и приближается к нормальному распределению по мере увеличения числа наблюдений. Поэтому применение критерия χ2 к оценке дискретных распределений сопряжено с некоторыми погрешностями, которые сказываются на его величине, особенно на малочисленных выборках. Для получения более точных оценок выборка, распределяемая в вариационный ряд, должна иметь не менее 50 вариантов. Правильное применение критерия χ2 требует также, чтобы частоты вариантов в крайних классах не были бы меньше 5; если их меньше 5, то они объединяются с частотами соседних классов, чтобы в сумме составляли величину большую или равную 5. Соответственно объединению частот уменьшается и число классов (N). Число степеней свободы устанавливается по вторичному числу классов с учетом числа ограничений свободы вариации.
Так как точность определения критерия χ2 в значительной степени зависит от точности расчета теоретических частот (Т), для получения разности между эмпирическими и вычисленными частотами следует использовать неокругленные теоретические частоты.
В качестве примера возьмем исследование, опубликованное на сайте, который посвящен применению статистических методов в гуманитарных науках.
Критерий "Хи-квадрат" позволяет сравнивать распределения частот вне зависимости от того, распределены они нормально или нет.
Под частотой понимается количество появлений какого-либо события. Обычно, с частотой появления события имеют дело, когда переменные измерены в шкале наименований и другой их характеристики, кроме частоты подобрать невозможно или проблематично. Другими словами, когда переменная имеет качественные характеристики. Так же многие исследователи склонны переводить баллы теста в уровни (высокий, средний, низкий) и строить таблицы распределений баллов, чтобы узнать количество человек по этим уровням. Чтобы доказать, что в одном из уровней (в одной из категорий) количество человек действительно больше (меньше) так же используется коэффициент Хи-квадрат.
Разберем самый простой пример.
Среди младших подростков был проведён тест для выявления самооценки. Баллы теста были переведены в три уровня: высокий, средний, низкий. Частоты распределились следующим образом:
Высокий (В) 27 чел.
Средний (С) 12 чел.
Низкий (Н) 11 чел.
Очевидно, что детей с высокой самооценкой большинство, однако это нужно доказать статистически. Для этого используем критерий Хи-квадрат.
Наша задача проверить, отличаются ли полученные эмпирические данные от теоретически равновероятных. Для этого необходимо найти теоретические частоты. В нашем случае, теоретические частоты – это равновероятные частоты, которые находятся путём сложения всех частот и деления на количество категорий.
В нашем случае:
(В + С + Н)/3 = (27+12+11)/3 = 16,6
Формула для расчета критерия хи-квадрат:
χ2 = ∑(Э - Т)І / Т
Строим таблицу:
Находим сумму последнего столбца:
Теперь нужно найти критическое значение критерия по таблице критических значений (Таблица 1 в приложении). Для этого нам понадобится число степеней свободы (n).
n = (R - 1) * (C - 1)
где R – количество строк в таблице, C – количество столбцов.
В нашем случае только один столбец (имеются в виду исходные эмпирические частоты) и три строки (категории), поэтому формула изменяется – исключаем столбцы.
n = (R - 1) = 3-1 = 2
Для вероятности ошибки p≤0,05 и n = 2 критическое значение χ2 = 5,99.
Полученное эмпирическое значение больше критического – различия частот достоверны (χ2= 9,64; p≤0,05).
Как видим, расчет критерия очень прост и не занимает много времени. Практическая ценность критерия хи-квадрат огромна. Этот метод оказывается наиболее ценным при анализе ответов на вопросы анкет.
Разберем более сложный пример.
К примеру, психолог хочет узнать, действительно ли то, что учителя более предвзято относятся к мальчикам, чем к девочкам. Т.е. более склонны хвалить девочек. Для этого психологом были проанализированы характеристики учеников, написанные учителями, на предмет частоты встречаемости трех слов: "активный", "старательный", "дисциплинированный", синонимы слов так же подсчитывались. Данные о частоте встречаемости слов были занесены в таблицу:
Для обработки полученных данных используем критерий хи-квадрат.
Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем:
Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s).
Итоговая таблица для вычислений будет выглядеть так:
χ2 = ∑(Э - Т)І / Т
n = (R - 1), где R – количество строк в таблице.
В нашем случае хи-квадрат = 4,21; n = 2.
По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99.
Полученное значение меньше критического, а значит принимается нулевая гипотеза.
Вывод: учителя не придают значение полу ребенка при написании ему характеристики.
Заключение.
К. Пирсон внёс значительный вклад в развитие математической статистики (большое количество фундаментальных понятий). Основная философская позиция Пирсона формулируется следующим образом: понятия науки - искусственные конструкции, средства описания и упорядочивания чувственного опыта; правила связи их в научные предложения вычленяются грамматикой науки, которая и является, философией науки. Связать же разнородные понятия и явления позволяет универсальная дисциплина - прикладная статистика, хотя и она по Пирсону субъективна.
Многие построения К. Пирсона напрямую связаны или разрабатывались с использованием антропологических материалов. Им разработаны многочисленные способы нумерической классификации и статистические критерии, применяемые во всех областях науки.
Литература.
1. Боголюбов А. Н. Математики. Механики. Биографический справочник. - Киев: Наукова думка, 1983.
2. Колмогоров А. Н., Юшкевич А. П. (ред.). Математика XIX века. - М.: Наука. - Т. I.
3. 3. Боровков А.А. Математическая статистика. М.: Наука, 1994.
4. 8. Феллер В. Введение в теорию вероятностей и ее приложения. - М.: Мир, Т.2, 1984.
5. 9. Харман Г., Современный факторный анализ. - М.: Статистика, 1972.
Распределение. Распределение Пирсона Плотность вероятности … Википедия
распределение «хи-квадрат» - распределение «хи квадрат» — Тематики защита информации EN chi square distribution … Справочник технического переводчика
распределение хи-квадрат - Распределение вероятностей непрерывной случайной величины с значениями от 0 до, плотность которого задается формулой, где 0 при параметре =1,2,...; – гамма функция. Примеры. 1) Сумма квадратов независимых нормированных нормальных случайных… … Словарь социологической статистики
РАСПРЕДЕЛЕНИЕ ХИ-КВАДРАТ (хи2) - Распределение случайной переменной хи2., если случайные выборки размера 1 взяты из нормального распределения со средним (и вариансой q2, то хи2 = (X1 u)2/q2, где X отобранное значение. Если объем выборки увеличивается произвольно до N, то хи2 =… …
Плотность вероятности … Википедия
- (Распределение Снедекора) Плотность вероятности … Википедия
Распределение Фишера Плотность вероятности Функция распределения Параметры числа с … Википедия
Одно из основных понятий вероятностей теории и математической статистики. При современном подходе в качестве математич. модели изучаемого случайного явления берется соответствующее вероятностное пространство{W, S, Р}, где W множество элементарных … Математическая энциклопедия
Гамма распределение Плотность вероятности Функция распределения Параметры … Википедия
РАСПРЕДЕЛЕНИЕ F - Теоретическое вероятностное распределение случайной переменной F. Если случайные выборки размера N отобраны независимо из нормальной популяции, каждая из них генерирует распределение хи квадрат со степенью свободы = N. Отношение двух таких… … Толковый словарь по психологии
Книги
- Теория вероятностей и математическая статистика в задачах: Более 360 задач и упражнений , Борзых Д.. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…
- Теория вероятностей и математическая статистика в задачах. Более 360 задач и упражнений , Борзых Д.А.. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…









- Белая мышь толкование по соннику
- Плавание, Юлия Ефимова: биография участницы Олимпиады в Рио
- Святой преподобный антоний римлянин, новгородский чудотворец
- Рецепт: Печенье "Кинако" - из соевой муки Соевая мука что
- Чем полезно соевое молоко для красоты и здоровья и как его приготовить дома Соевое молоко из соевых бобов
- Имитированная икра: из чего её делают, польза и вред
- Рецепт: Мясные клубочки - в слоеном тесте запеченные в духовом шкафу Ингредиенты на мясные клубочки в слоеном тесте
- Замороженная вишня – калорийность продукта; как заготовить на зиму в домашних условиях с видео; применение в кулинарии; польза и вред
- Лев и Близнецы: совместимость двух сильных знаков Лев и близнецы гороскоп
- Интересные факты о киевском софийском соборе
- Фенол сообщение. Применение фенола. Физические свойства фенола
- Рубль — круглый: смотри, чтоб не укатился
- Какие желания можно загадать?
- Андреевская церковь – шедевр архитектурного стиля барокко
- К чему снится лошадь женщине, незамужней девушке, беременной?
- Как приготовить сырный крекер
- Гороскоп — Весы Гороскоп с 18 по 25 сентября
- К чему снятся татуировки: значение сна
- Икона спиридона тримифунтского в чем помогает
- День народного единства - история появления праздника